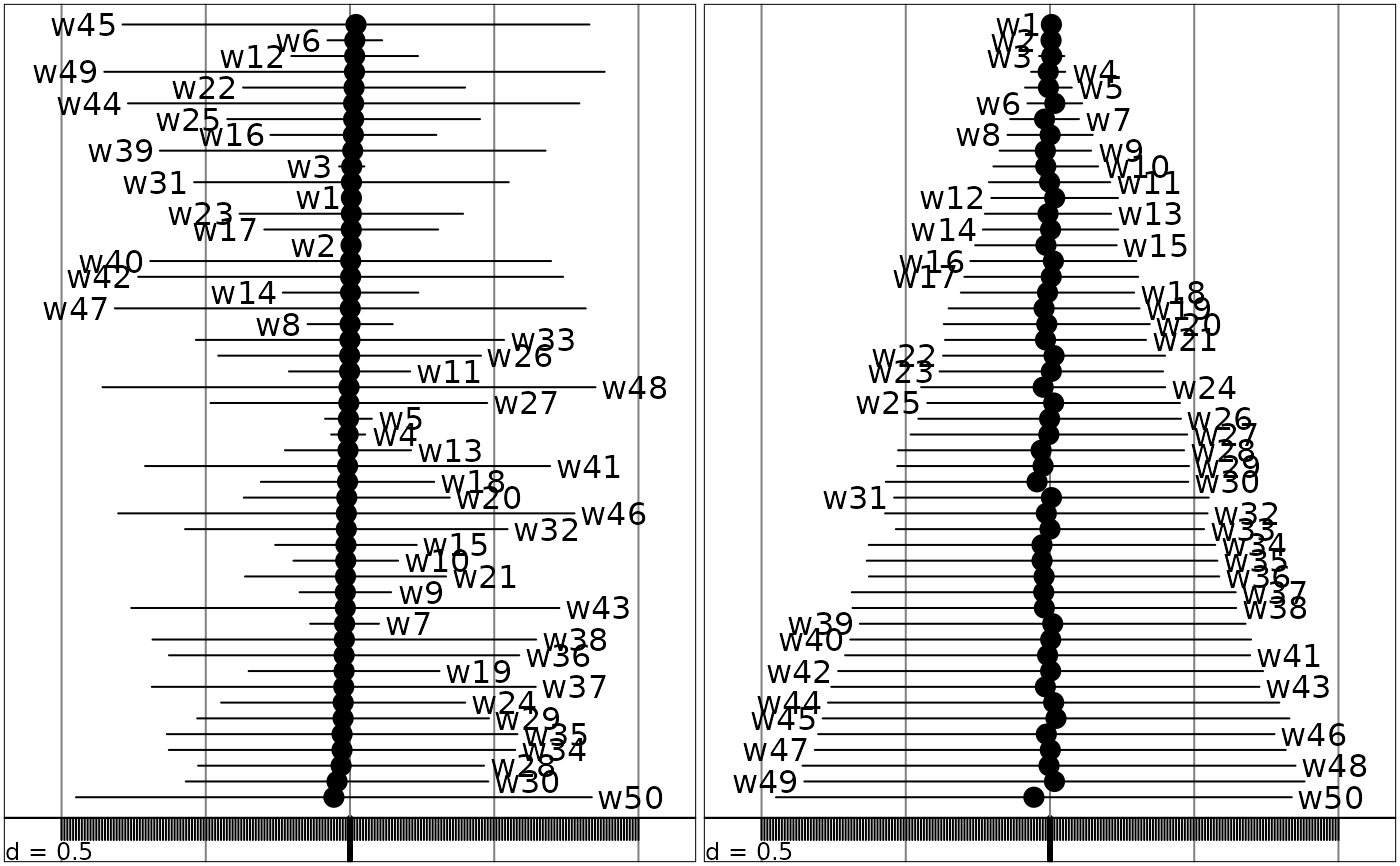
Representation by mean- standard deviation of a set of weight distributions on a numeric score
sco.distri.Rdrepresents the mean- standard deviation of a set of weight distributions on a numeric score.
Usage
sco.distri(score, df, y.rank = TRUE, csize = 1, labels = names(df),
clabel = 1, xlim = NULL, grid = TRUE, cgrid = 0.75,
include.origin = TRUE, origin = 0, sub = NULL, csub = 1)Arguments
- score
a numeric vector
- df
a data frame with only positive or null values
- y.rank
a logical value indicating whether the means should be classified in ascending order
- csize
an integer indicating the size segment
- labels
a vector of strings of characters for the labels of the variables
- clabel
if not NULL, a character size for the labels, used with
par("cex")*clabel- xlim
the ranges to be encompassed by the x axis, if NULL they are computed
- grid
a logical value indicating whether the scale vertical lines should be drawn
- cgrid
a character size, parameter used with
par("cex")*cgridto indicate the mesh of the scale- include.origin
a logical value indicating whether the point "origin" should be belonged to the graph space
- origin
the fixed point in the graph space, for example c(0,0) the origin axes
- sub
a string of characters to be inserted as legend
- csub
a character size for the legend, used with
par("cex")*csub
Examples
if(!adegraphicsLoaded()) {
w <- seq(-1, 1, le = 200)
distri <- data.frame(lapply(1:50,
function(x) sample((200:1)) * ((w >= (- x / 50)) & (w <= x / 50))))
names(distri) <- paste("w", 1:50, sep = "")
par(mfrow = c(1, 2))
sco.distri(w, distri, csi = 1.5)
sco.distri(w, distri, y.rank = FALSE, csi = 1.5)
par(mfrow = c(1, 1))
data(rpjdl)
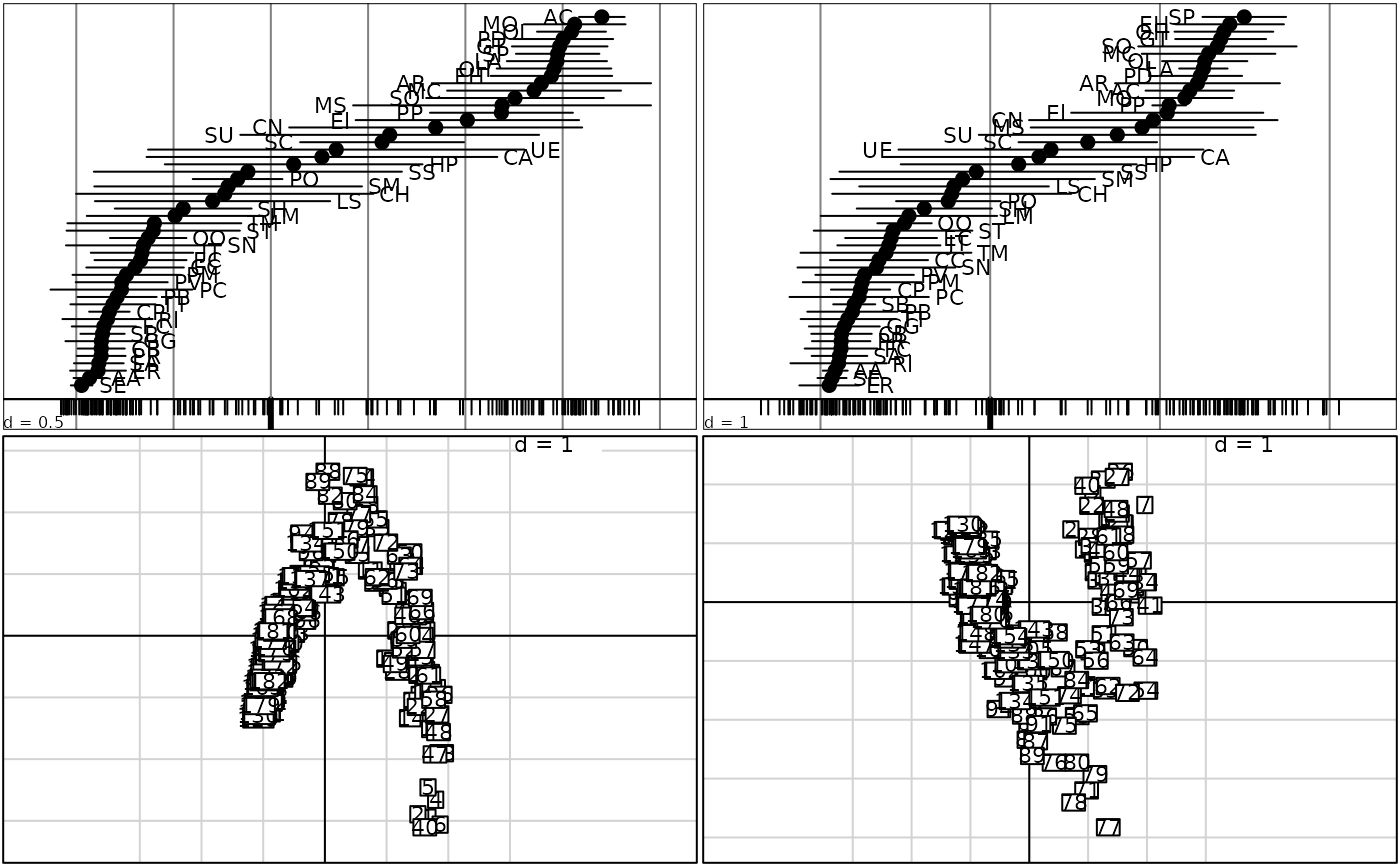
coa2 <- dudi.coa(rpjdl$fau, FALSE)
sco.distri(coa2$li[, 1], rpjdl$fau, lab = rpjdl$frlab, clab = 0.8)
data(doubs)
par(mfrow = c(2, 2))
poi.coa <- dudi.coa(doubs$fish, scann = FALSE)
sco.distri(poi.coa$l1[, 1], doubs$fish)
poi.nsc <- dudi.nsc(doubs$fish, scann = FALSE)
sco.distri(poi.nsc$l1[, 1], doubs$fish)
s.label(poi.coa$l1)
s.label(poi.nsc$l1)
data(rpjdl)
fau.coa <- dudi.coa(rpjdl$fau, scann = FALSE)
sco.distri(fau.coa$l1[,1], rpjdl$fau)
fau.nsc <- dudi.nsc(rpjdl$fau, scann = FALSE)
sco.distri(fau.nsc$l1[,1], rpjdl$fau)
s.label(fau.coa$l1)
s.label(fau.nsc$l1)
par(mfrow = c(1, 1))
}